Overview
Langfuse provides comprehensive observability for LLM applications with tracing, debugging, and dataset management capabilities. Composo delivers deterministic, accurate evaluation through purpose-built generative reward models that achieve 92% accuracy (vs 72% for LLM-as-judge). Together, they enable you to:- ✅ Track every LLM interaction through Langfuse’s tracing
- ✅ Add deterministic evaluation scores to your traces
- ✅ Evaluate datasets programmatically with reliable metrics
- ✅ Ship AI features with confidence using quantitative, trustworthy metrics
Prerequisites
Python
Python
How Langfuse & Composo work in combination
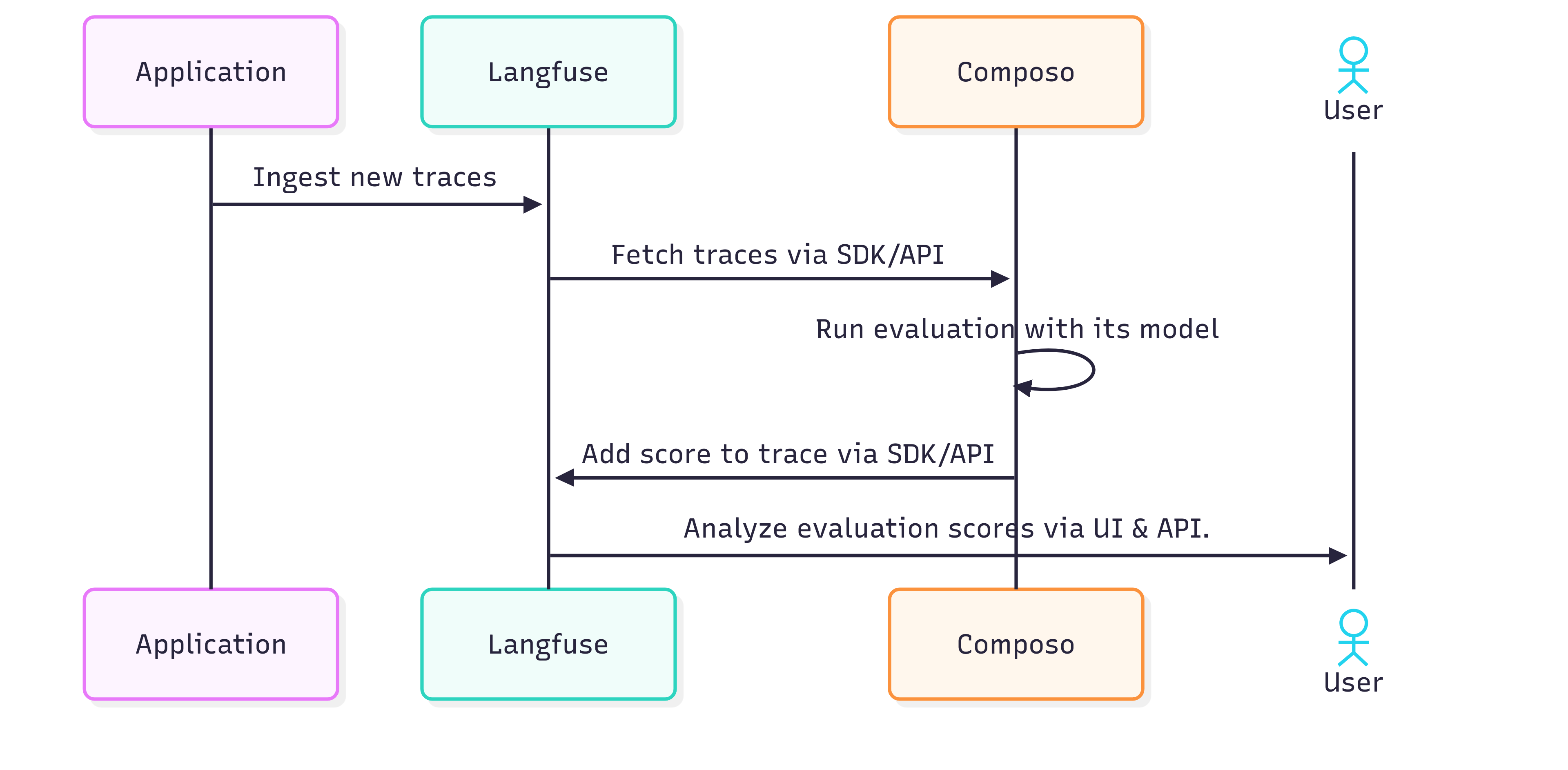
Method 1: Real-time Trace Evaluation
Evaluate LLM outputs as they’re generated in production or development. This approach uses the@observe decorator to automatically trace your LLM calls, then evaluates them with Composo asynchronously.
More detail on how the langfuse @observe decorator works is here.
When to use
- Production monitoring with real-time quality scores
- Development iteration with immediate feedback
Implementation
Python
Python
Method 2: Dataset Evaluation
Use this method to evaluate your LLM application on a dataset that already exists in Langfuse. Theitem.run() context manager automatically links execution traces to dataset items.
For more detail on how this works from Langfuse please see here.
When to use
- Testing prompt or model changes on existing Langfuse datasets
- Running experiments that you want to track in Langfuse UI
- Creating new dataset runs for comparison
- Regression testing with immediate Langfuse visibility
Implementation
Python
Method 3: Evaluating New Datasets
Use this method to evaluate datasets that don’t yet exist in Langfuse. You can create your own dataset locally, evaluate it with Composo, and log both the traces and evaluation scores to Langfuse for UI interpretation.When to use
- Evaluating new datasets before uploading to Langfuse
- Quick experimentation with custom datasets
- Batch evaluation of local test cases
- Creating baseline evaluations for new use cases
Implementation
Please see this notebook for the implementation approach for this.Method Selection Recap
- Use Method 1 for real-time production monitoring
- Use Method 2 for evaluating existing Langfuse datasets
- Use Method 3 for evaluating new datasets that don’t yet exist in Langfuse
Resources
- 📊 Langfuse Dataset Runs Documentation - applicable for method 2
- 🎯 Composo Documentation
- 💬 Get Support
Next Steps
- Start with Method 1 for immediate feedback during development
- Use Method 2 to run experiments on datasets in Langfuse
- Apply Method 3 to evaluate new datasets before uploading to Langfuse